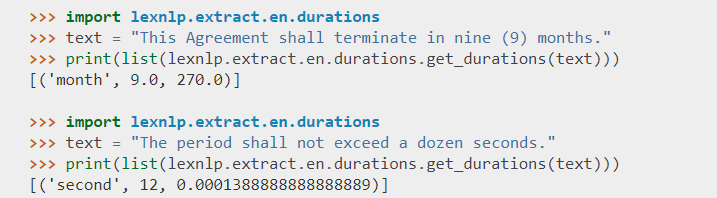
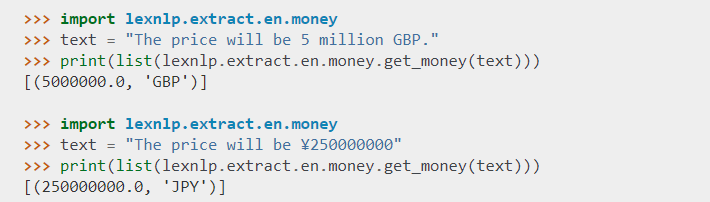
Tokenizes and Segments Text
Other libraries struggle with headings and sections, or they stumble over common abbreviations like “U.S.C.” LexNLP tokenizes and segments, leaving nothing behind:
- Pages
- Paragraphs
- Sentences
- Tokens, stems, and stopwords
- Titles
- Articles and sections
- Exhibits and schedules
- Table of contents